2026年4月9日 | 技术科普 · 代码示例 · 面试要点
一、开篇引入
如果你是一名开发者或内容创作者,AI小说助手 可能已经在你的工具库里占据了一席之地。无论是辅助扩写、续写情节,还是生成爆款文案,这些工具正在重塑创作流程。根据QYResearch数据,2025年全球AI小说写作工具市场规模约为1.79亿美元,预计到2032年将增长至3.61亿美元,年复合增长率达10.7%-31。但问题也随之而来:为什么AI生成的小说“局部合理、整体平庸”?为什么AI总写出“标准爽文味”却缺乏真正的灵魂?面试官问起LLM原理和RAG的区别时,你能否答出踩分点?
本文将从底层原理出发,系统拆解 AI小说助手 的核心技术——大语言模型(LLM)、多Agent协同架构、MoE混合专家模型,配合代码示例和高频面试题,帮你建立完整知识链路。核心目标只有一个:让你不但会用,而且懂原理、能讲清、会答题。
二、痛点切入:为什么需要AI小说助手?
传统写作方式的困境
传统小说创作中,作者需要同时处理大纲规划、角色设定、情节推进、文风统一等多个维度的任务。一个典型的中长篇创作流程大致如下:
传统写作流程示意 def write_novel_traditional(): outline = manual_outline() 人工构思大纲(耗时数周) characters = design_characters() 人工设定角色(耗时数天) for chapter in chapters: draft = write_manually(chapter) 人工逐字逐句写作 revise = revise_by_hand(draft) 人工反复修改 check_consistency(chapter) 人工检查前后一致性 问题:效率低、易疲劳、一致性难保证
传统写作的三个痛点:
创作瓶颈频繁:卡文、词穷是常态,灵感枯竭时效率骤降
前后一致性难以维持:长篇连载中,角色性格、伏笔细节容易“走形”
高重复性劳动占比大:大量时间花在扩写、润色、资料查阅上,而非核心创意
旧有技术方案的局限
在LLM大规模应用之前,已有的“写作辅助工具”主要包括:关键词联想工具、句式模板库、语法检查器等。这些工具的问题在于:
没有真正的“理解”能力:只能做局部词句替换,无法理解剧情逻辑
无法维持长篇一致性:不具备跨章节的记忆能力
缺乏创意生成能力:只能辅助润色,不能辅助构思
AI小说助手的出现
AI小说助手正是为了解决上述问题而出现的。其核心价值在于:
打破创作瓶颈:提供情节建议、场景扩写、对话生成
维持内容一致性:通过上下文管理技术,记住已创作内容
提升创作效率:将重复性劳动自动化,让创作者聚焦创意
三、核心概念讲解:大语言模型(LLM)
标准定义
大语言模型(Large Language Model,LLM) ,本质上是一个在海量文本数据上训练出来的概率计算系统-5。
拆解关键词:
“大” :参数量通常在数十亿到数万亿级别。例如,文心5.0的参数规模已达2.4万亿-
“语言” :模型学习的对象是自然语言的统计规律
“模型” :本质上是一个经过训练的数学函数,而非具有意识的“实体”
生活化类比
想象一个“超级打字员”,它读过互联网上几乎所有的书籍、文章、对话。当你给它前一句话时,它会根据“经验”推测下一句最可能出现的词。它不是在理解你在说什么,而是在统计预测大概率会接什么。
核心机制:Next Token Prediction(下一个词预测)
AI生成文本的核心机制只有四个字:Next Token Prediction-5。
LLM生成文本的核心机制 def llm_generate(prompt): """ 输入:用户提示词 输出:生成的文本 本质:每一步都预测"下一个最可能出现的词" """ tokens = tokenize(prompt) while not is_complete(): Step 1: 基于当前所有token,计算下一个token的概率分布 probability_distribution = model.predict_next_token(tokens) Step 2: 从概率分布中选择下一个token(采样) next_token = sample_from_distribution(probability_distribution) Step 3: 将新token追加到序列 tokens.append(next_token) 整篇小说就是这样一步一步预测出来的 它不是在构思剧情,而是在不断做局部概率最优选择 return detokenize(tokens)
为什么AI生成的小说“局部合理、整体平庸”?
因为它擅长局部预测,不擅长全局规划。AI生成的小说通常在单句层面读起来流畅自然,但整体剧情结构往往平铺直叙、缺少真正的“起承转合”-5。
幻觉现象(Hallucination)
AI编造事实却表达得非常自信,这种现象被称为“幻觉”。为什么会这样?因为AI的目标不是“真实”,而是生成“看起来合理”的文本-5。
幻觉产生的机制示意 def hallucination_mechanism(): """ 当训练数据中某种表达结构概率很高,但具体信息缺失时, AI会自动补全一个"最像真的"版本 """ 输入:"根据《XX史料》记载,这场战争发生在..." 如果训练数据中没有具体的战争时间 AI会基于概率生成一个看似合理的时间(可能是错误的) 但它不会告诉你"我不知道",而是"自信地"编造
应对策略:在工程级使用中,一定要有人类校验层,形成“生成→检测→结构校验→人工重构”的闭环-5。
四、关联概念讲解:AI智能体(Agent)
标准定义
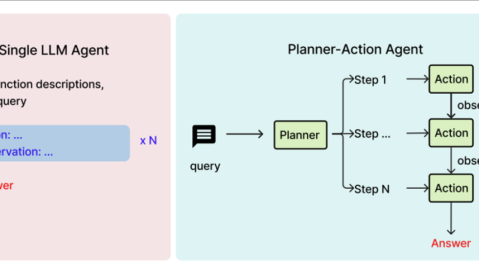
AI智能体(Agent) ,是指能够自主感知环境、进行推理决策、并执行动作以完成特定任务的AI系统。与单纯的LLM不同,Agent具备了 Reasoning(推理)和Acting(执行) 的双重基因-。
Agent与LLM的关系
| 维度 | LLM | Agent |
|---|---|---|
| 核心能力 | 文本生成与理解 | 感知+推理+执行 |
| 能否操作外部系统 | 不能 | 能(调用API、打开浏览器、操作数据库等) |
| 是否有“行动闭环” | 单次输入→单次输出 | 循环:观察→思考→行动→再观察 |
| 典型场景 | 回答问题、生成内容 | 自动化流程、复杂任务分解 |
多Agent协同架构
在AI小说写作领域,多Agent协同架构 已成为2026年的技术主流。其核心思想是将创作流程拆解为多个专业Agent,各司其职并实现数据互通-3。
多Agent协同写作架构示意 class MultiAgentWritingSystem: """ 典型的多Agent小说写作架构 每个Agent专注于特定环节 """ def __init__(self): 情节构思Agent:负责剧情走向和冲突设计 self.plot_agent = PlotPlanningAgent() 文风适配Agent:负责风格控制和语言润色 self.style_agent = StyleAdaptationAgent() 细节填充Agent:负责场景描写和对话生成 self.detail_agent = DetailFillingAgent() def write_chapter(self, outline, character_profile): Step 1: 情节Agent生成章节大纲 chapter_plan = self.plot_agent.plan(outline) Step 2: 细节Agent基于大纲生成初稿 draft = self.detail_agent.generate(chapter_plan, character_profile) Step 3: 风格Agent进行润色和风格统一 final_text = self.style_agent.polish(draft) return final_text
实际应用案例
2026年3月,阅文集团旗下“作家助手”接入OpenClaw(“龙虾”),成为网文创作工具中首家部署AI智能体的平台。作家可以“领养”专属AI智能体,一键完成热梗素材收集、情节评论分析、作品运营等事务性工作,真正实现“一人成军”-30。
五、概念关系与区别总结
LLM vs Agent:思想 vs 实现
用一句话概括:LLM是“大脑”,Agent是“大脑+手”。
LLM提供认知能力:理解语言、生成文本、推理分析
Agent赋予行动能力:调用工具、执行操作、完成任务闭环
更精确的关系定位:
┌─────────────────────────────────────────┐ │ Agent(智能体) │ │ ┌─────────────────────────────────┐ │ │ │ LLM(核心大脑) │ │ │ │ • 理解语言 │ │ │ │ • 生成文本 │ │ │ │ • 推理分析 │ │ │ └─────────────────────────────────┘ │ │ • 工具调用(Tool Use) │ │ • 任务规划(Planning) │ │ • 记忆管理(Memory) │ └─────────────────────────────────────────┘
记忆要点
LLM是基础能力提供者,Agent是能力编排与执行者。没有LLM的Agent是“空壳”,没有Agent的LLM是“纸上谈兵”。
六、代码/流程示例:从0到1实现AI小说助手核心逻辑
示例1:使用LLM进行小说续写
""" 极简示例:基于LLM API的小说续写 (以OpenAI风格API为例,实际使用时替换为相应接口) """ import openai def ai_novel_continuation(prompt: str, max_tokens: int = 500) -> str: """ 功能:基于用户输入的前文,让AI生成后续内容 核心:就是Next Token Prediction的工程封装 """ Step 1: 构建对话消息(包含系统角色设定) messages = [ { "role": "system", "content": "你是一位专业的小说家,擅长网络小说创作。" }, { "role": "user", "content": f"请续写以下小说内容:\n{prompt}" } ] Step 2: 调用LLM API(实际使用中需配置API Key) response = openai.ChatCompletion.create( model="gpt-4-turbo", 或使用其他LLM messages=messages, max_tokens=max_tokens, temperature=0.8, 控制随机性,值越高越有创意 top_p=0.9, 核采样,控制词汇选择范围 ) Step 3: 提取并返回生成内容 continuation = response.choices[0].message.content return continuation 使用示例 prompt = "夜色如水,他握紧了手中的" result = ai_novel_continuation(prompt) print(result) 可能的输出:剑/刀/手机/钥匙...取决于概率分布
示例2:基于RAG的知识增强写作
""" RAG增强的小说写作:让AI基于参考素材生成内容 解决纯LLM生成"内容空洞"的问题 """ from typing import List import numpy as np class RAGEnhancedWriter: """ RAG = Retrieval-Augmented Generation(检索增强生成) 核心思想:生成前先从知识库中检索相关信息 """ def __init__(self, knowledge_base: List[str], embedding_model): self.knowledge_base = knowledge_base 知识库(如设定集、世界观文档) self.embedding_model = embedding_model 向量化模型 def retrieve_relevant_context(self, query: str, top_k: int = 3) -> List[str]: """ 检索阶段:从知识库中找出与当前查询最相关的内容 """ 将查询向量化 query_embedding = self.embedding_model.encode(query) 计算与知识库中所有内容的相似度 similarities = [] for doc in self.knowledge_base: doc_embedding = self.embedding_model.encode(doc) sim = np.dot(query_embedding, doc_embedding) similarities.append(sim) 返回最相关的top_k个文档 top_indices = np.argsort(similarities)[-top_k:][::-1] return [self.knowledge_base[i] for i in top_indices] def generate_with_rag(self, prompt: str, llm_model) -> str: """ 生成阶段:将检索结果作为上下文喂给LLM 相当于:考试时给你一本参考书,你边翻边答 """ Step 1: 检索相关知识 relevant_contexts = self.retrieve_relevant_context(prompt) Step 2: 将检索结果拼接到Prompt中 enhanced_prompt = f""" 【参考素材】: {' '.join(relevant_contexts)} 【创作任务】: {prompt} 请基于以上参考素材进行创作,确保不违背世界观设定。 """ Step 3: 调用LLM生成 return llm_model.generate(enhanced_prompt)
新旧方式对比:
| 对比维度 | 纯LLM生成 | RAG增强生成 |
|---|---|---|
| 内容准确性 | 依赖模型内部知识 | 可引用外部知识库 |
| 知识时效性 | 训练数据截止日期后即过时 | 可实时更新知识库 |
| 幻觉风险 | 较高 | 较低(有参考约束) |
| 个性化程度 | 通用风格 | 可定制风格和设定 |
七、底层原理/技术支撑
AI小说助手的底层能力依赖于以下几项关键技术:
1. Transformer架构与自注意力机制
Transformer是LLM的架构基石,其核心是 自注意力机制(Self-Attention) ,让模型能够在处理一个词时,“关注”到句子中其他相关词的位置关系。这正是LLM能够理解长距离依赖的关键——不再像RNN那样“记不住前面说了什么”-36。
2. 预训练 + 微调范式
预训练:在大规模无标注语料上训练,学习语言通用规律
微调:在特定任务数据上继续训练,让模型“学会”听人话
3. MoE混合专家架构
2026年的主流大模型广泛采用 混合专家模型(Mixture of Experts,MoE) 架构。它将模型参数拆分至多个专业“专家模块”,不同模块分别负责逻辑推理、语言润色、事实核查等任务,生成文本时动态调用对应模块,既提升响应速度,又保证内容的逻辑性与准确性-3。
4. 对齐技术:RLHF与DPO
通过强化学习与人类反馈(Reinforcement Learning from Human Feedback, RLHF)和直接偏好优化(Direct Preference Optimization, DPO)等技术,使模型输出更符合人类期望,减少“一本正经胡说八道”的情况-3-36。
八、高频面试题与参考答案
💡 以下题目是2026年大模型相关岗位面试中的高频考点,建议理解原理后用自己的话复述,而非死记硬背。
面试题1:LLM的核心原理是什么?
参考答案:
LLM的本质是一个“预测下一个词”的概率模型。它通过海量文本训练,学会在给定上下文时预测下一个最可能出现的词。关键机制有三个:
Transformer架构:自注意力机制让模型能捕捉长距离依赖
预训练 + 微调范式:先在大规模语料上预训练,再在特定任务上微调
对齐技术:RLHF、DPO等方法让模型输出更符合人类期望
面试题2:RAG和微调的区别是什么?如何选择?
参考答案:
RAG(检索增强生成) :在生成答案前先从外部知识库检索相关信息,相当于考试时给你一本参考书边翻边答
微调(Fine-tuning) :在特定领域数据上继续训练模型,改变模型参数,相当于考前把知识背进脑子里
选择逻辑:
知识频繁更新、需要可解释性 → RAG
需要特定写作风格、领域深度 → 微调
生产系统中往往两者结合:RAG保证时效性,微调保证风格一致性
面试题3:RAG的检索质量不行怎么办?
参考答案:
检索阶段优化:换更好的Embedding模型、做查询改写、引入混合检索(向量+关键词)
召回阶段优化:调整chunk大小、做重排序
生成阶段兜底:在Prompt中明确告知“如果检索结果不相关就说不知道”,设置置信度阈值
面试题4:AI小说助手如何解决“长文本逻辑断裂”问题?
参考答案:
主要通过三个技术手段:
动态上下文窗口:最大支持200K token输入,可完整处理长篇小说-3
多Agent协同:将创作拆解为情节构思、文风适配、细节填充等模块-3
知识图谱支撑:构建网文知识图谱,维护跨章节的人设一致性与伏笔记忆-3
面试题5:什么是MoE架构?它在AI写作中有什么优势?
参考答案:
MoE(混合专家模型)将模型参数拆分至多个专业“专家模块”,不同模块分别负责不同任务,生成文本时动态调用对应模块。优势包括:
提升效率:每次推理只激活部分参数,降低计算成本
增强专业性:各模块可以深度优化特定能力
提高响应速度:API调用延迟可低至50ms-3
九、结尾总结
核心知识点回顾
| 核心概念 | 一句话总结 |
|---|---|
| LLM(大语言模型) | 一个预测下一个词的概率计算系统,而非“思想者” |
| Next Token Prediction | 逐词预测的生成机制,解释为何“局部合理、整体平庸” |
| 幻觉(Hallucination) | AI为追求“合理”而编造事实的机制性缺陷 |
| Agent(智能体) | 具备推理和执行能力的LLM,能调用工具完成任务 |
| RAG(检索增强生成) | 生成前先检索,解决知识时效性和幻觉问题 |
| MoE(混合专家模型) | 拆分专家模块,提升效率和专业性 |
重点与易错点提示
不要把LLM拟人化:它不是“理解”,而是“概率计算”
RAG和微调不是二选一:实际生产中往往是两者结合
幻觉不是bug:它是LLM工作机制的固有特征,需要工程手段应对
进阶方向预告
下一篇文章将深入探讨 “人主AI辅”的工程级写作流程,包括:大纲如何人写、角色核心驱动力如何人设、冲突如何不被AI生成、以及提示词工程的高级技巧-8。敬请期待!
如果觉得本文对你有帮助,欢迎点赞、收藏、分享给需要的朋友。有任何疑问或想了解的技术方向,欢迎留言讨论。