发布时间:2026年4月10日 14:30 北京时间
引言:AI志愿填报已成必学知识点

在高考志愿填报领域,AI推荐技术正逐步替代传统人工筛选和静态数据库查询,成为新一代志愿填报系统的核心引擎。从长沙本地创客基于大语言模型开发的智能填报助手,到湖南工商大学依托DeepSeek大模型上线的“AI报考智能助手”,AI志愿填报正从“概念炒作”走向“规模化落地”。许多开发者在接触这一领域时常常面临同样的困惑:协同过滤、内容过滤、图嵌入这些推荐算法到底怎么选?“冲稳保”推荐的底层逻辑是什么?RAG和多智能体协同又是如何提升推荐准确率的?面试时被问到“AI志愿推荐系统的核心算法”该如何回答?本文将从痛点切入→核心概念→关系梳理→代码示例→底层原理→面试要点六个层面,带你建立完整的知识链路。
一、痛点切入:为什么需要AI志愿推荐算法?
传统志愿填报的落后实现方式
在AI技术普及之前,绝大多数志愿填报系统停留在“信息陈列阶段”,本质上只是将历年分数线、院校名录进行电子化聚合。
传统实现:简单的分数阈值筛选 def traditional_recommend(score, school_list): recommendations = [] for school in school_list: if school['min_score'] <= score: 仅判断最低分数线 recommendations.append(school) return recommendations[:10] 返回前10个
上述代码的核心逻辑极其简陋:仅通过考生的分数与各院校的最低录取分数线做简单的数值比较。现实中的录取决策远比这复杂——各院校和专业之间存在大量“隐性匹配规则”,如专业热度、招生计划变化、大小年波动、选科组合限制等,这些都是简单阈值筛选无法处理的。
传统方案的三大致命缺陷
信息孤岛效应:静态数据库缺乏动态关联分析能力,无法预警“大小年”波动、专业就业趋势拐点等关键变量,这正是导致考生高分滑档的深层技术症结-33。
决策效率低下:考生面对海量信息陷入决策瘫痪,传统的长表单填报方式将平均决策时长拖至12小时以上-33。
推荐同质化严重:早期引入的协同过滤算法依赖历史录取数据建模,对政策突变(如新高考选科要求)响应滞后,且存在“推荐同质化”风险——相似分数的考生获得几乎完全相同的院校列表-33。
正是为了解决这些问题,长沙AI志愿助手这类基于大模型和智能推荐算法的工具应运而生。
二、核心概念讲解:协同过滤(Collaborative Filtering)
定义
协同过滤(Collaborative Filtering, CF) 是一种基于用户行为相似性的推荐算法,核心思想是“物以类聚,人以群分”——与你相似的人喜欢的东西,你也很可能喜欢。
在志愿填报场景中的应用
在AI志愿填报系统中,协同过滤通过分析大量历史考生的“分数-位次-填报院校-录取结果”数据,构建用户-院校评分矩阵,找出与你最相似的“考生群体”,然后将这些相似考生最终被录取的院校推荐给你。
生活化类比
想象你走进一家书店,店员没有问你任何问题,只是默默观察了你的浏览记录,然后对你说:“之前来这里的客人,和你一样先翻了《三体》又看了《流浪地球》的,最后有80%都买了《乡村教师》。”——这就是协同过滤。
两类协同过滤详解
基于用户(User-based CF) :找到与当前考生填报行为相似的其他考生,推荐他们青睐的院校。适用于用户数量相对稳定的场景。
基于物品(Item-based CF) :找到与考生感兴趣的院校相似的院校进行推荐。例如,某考生关注了计算机科学与技术专业,系统会推荐电子信息工程、软件工程等相关专业。这种方式在志愿填报中更为常用,因为院校和专业的“相似性”相对稳定,计算效率更高。
三、关联概念讲解:内容过滤(Content-based Filtering)
定义
内容过滤(Content-based Filtering, CBF) 是一种基于物品属性特征的推荐算法,核心思想是“你喜欢什么,就给你推荐什么”——根据用户的历史偏好,分析其喜欢的物品的共性特征,然后推荐具有相似特征的其他物品。
与协同过滤的关系:互补而非互斥
协同过滤和内容过滤的关系可以这样理解:
协同过滤是“人的相似性”,内容过滤是“物的相似性”;协同过滤回答“和你一样的人选了啥”,内容过滤回答“你喜欢的类型还有哪些”。
协同过滤:依靠群体行为数据,发现用户之间或物品之间的隐含关联。
内容过滤:依靠物品自身的属性特征(如院校层级、地理位置、学科评估等级),进行显式匹配。
在志愿填报中的实现
内容过滤示例:基于考生偏好的院校特征匹配 def content_based_recommend(user_prefs, school_features): scores = [] for school in school_features: 计算偏好与院校特征的余弦相似度 similarity = cosine_similarity(user_prefs, school['vector']) scores.append((school['name'], similarity)) return sorted(scores, key=lambda x: x[1], reverse=True)[:10]
院校特征向量可以包含:城市等级、学科评估等级、是否为985/211、近三年录取位次波动系数等多维属性。系统根据考生对“地域偏好”“学校层次偏好”等维度的权重配置,计算匹配度。
四、概念关系与区别总结
| 维度 | 协同过滤(CF) | 内容过滤(CBF) |
|---|---|---|
| 核心思想 | 人相似 → 喜好相似 | 物相似 → 喜好延续 |
| 数据依赖 | 需要大量用户行为数据 | 需要物品属性数据 |
| 冷启动问题 | 存在(新用户/新物品无数据) | 较轻(新物品有属性即可推荐) |
| 推荐多样性 | 较好 | 较差,容易同质化 |
| 可解释性 | 较弱(“因为用户A也选了”) | 较强(“因为您喜欢理工类院校”) |
一句话记忆:协同过滤是“社会证明”,内容过滤是“个人偏好延续”;现代AI志愿填报系统通常采用混合推荐策略,将两者结合以达到最佳效果-28。
五、代码示例:从传统到AI推荐的演进
步骤一:数据预处理与特征工程
import pandas as pd from sklearn.preprocessing import MinMaxScaler from sklearn.metrics.pairwise import cosine_similarity 1. 构建考生特征向量(分数、位次、选科组合编码) student_data = { 'score': [650], 'rank': [2500], 'subject_code': [1] 1:物理类, 2:历史类 } student_df = pd.DataFrame(student_data) 2. 构建院校特征矩阵(近三年最低位次、学科评估等级、城市热度指数) school_data = pd.DataFrame({ 'school_id': range(1, 101), 'min_rank_2023': [...], 2023年最低录取位次 'min_rank_2024': [...], 2024年最低录取位次 'subject_score': [...], 学科评估得分(0-100) 'city_score': [...] 城市吸引力得分(0-100) })
步骤二:混合推荐算法核心逻辑
def hybrid_recommend(student, schools, cf_weight=0.5, cb_weight=0.5): """ 混合推荐:协同过滤 + 内容过滤加权融合 关键参数权重可动态调整,适应不同场景需求 """ 协同过滤部分:基于相似考生群体的录取统计 similar_students = find_similar_students(student) 返回相似考生列表 cf_scores = collaborative_filter(similar_students) 返回院校推荐分数 内容过滤部分:基于考生偏好与院校特征的匹配度 cb_scores = content_filter(student['preferences'], schools) 加权融合 final_scores = {} for school_id in schools['school_id']: final_scores[school_id] = cf_weight cf_scores.get(school_id, 0) + \ cb_weight cb_scores.get(school_id, 0) 返回排序后的推荐列表 return sorted(final_scores.items(), key=lambda x: x[1], reverse=True)
步骤三:生成“冲稳保”志愿方案
系统根据录取概率预测,将推荐院校分为三个梯队:
冲(录取概率10%-30%) :位次略高于考生当前水平的名校,值得冒险冲刺。
稳(录取概率40%-70%) :与考生位次匹配度高的院校,核心选择区域。
保(录取概率80%以上) :位次明显低于考生水平的院校,确保有学上。
这种分层策略结合历年录取大数据与AI算法,能够精准推荐冲刺、稳妥、保底的院校组合-2。
六、底层原理与技术支撑
核心技术栈一览
| 技术方向 | 具体实现 | 作用 |
|---|---|---|
| 推荐算法 | 协同过滤 + 内容过滤 + 图嵌入(Graph Embedding) | 精准匹配考生与院校 |
| 大模型应用 | 大语言模型(LLM)+ RAG(检索增强生成) | 智能问答与方案解读 |
| 时序预测 | LSTM神经网络 + 马尔科夫链蒙特卡洛(MCMC) | 录取概率动态预测 |
| 知识图谱 | 专业-院校-职业多维度关联图谱 | 揭示隐性关联链条 |
底层关键技术详解
1. 图嵌入技术(Graph Embedding) :当前最前沿的AI志愿填报系统采用基于图嵌入的算法,利用历史录取大数据,挖掘全量院校和专业之间更深层次的关联和规律,通过图嵌入来构建和分析院校专业的关联图,探寻在录取难度上具有相似性的专业集群,从而为考生提供更丰富的“替代”或“对标”选项-。
2. RAG(检索增强生成) :现代高考大模型系统融合RAG技术、多智能体协同与引擎能力,实现从信息查询到志愿决策的智能化升级。通过搭建RAG技术管线,引入引擎辅助大模型生成环节,显著提升推荐结果的权威性与时效性-13。
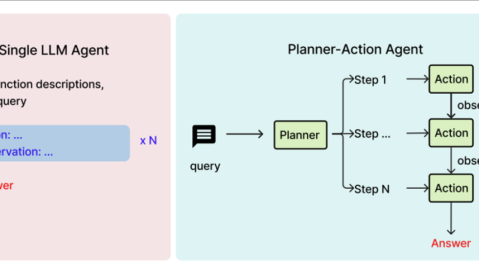
3. 多智能体协同(Multi-Agent Collaboration) :基于LangGraph等框架,构建包含专家Agent、评分机制、组件的智能体协同网络,提升系统稳定性与可扩展性-13。
4. 深度学习与预测模型:前沿平台通过时序预测模型(如LSTM神经网络)模拟录取概率波动,用知识图谱技术揭示“专业-职业-城市”隐性关联链-33。部分系统采用马尔科夫链蒙特卡洛模拟技术,结合职业路径规划模块,推荐方案的一志愿录取率较传统方法提高22%-。
七、高频面试题与参考答案
Q1:请简述AI志愿填报推荐系统的核心算法架构。
标准答案:现代AI志愿填报推荐系统采用三层递进架构——底层是基于历史录取大数据的协同过滤,中层是结合考生偏好的内容过滤,上层是大模型驱动的个性化解读与问答。具体包括:(1)协同过滤模块,基于相似考生群体的录取统计;(2)内容过滤模块,基于院校特征与考生偏好的匹配度;(3)图嵌入模块,挖掘院校专业之间的深层关联;(4)RAG增强模块,结合引擎提升推荐权威性。
踩分点:提到分层架构 + 具体算法名称 + RAG/多智能体等前沿技术。
Q2:协同过滤和内容过滤在志愿填报场景中如何选择?各自的优缺点是什么?
标准答案:
协同过滤适合数据积累充分的场景,能发现隐性关联,但存在冷启动和推荐同质化问题。
内容过滤适合新院校或新专业的推荐,可解释性强,但容易导致信息茧房。
实际应用中采用混合策略,动态调整权重,兼顾准确性与多样性。
踩分点:对比清晰 + 提到“混合推荐”是关键答案。
Q3:如何处理AI志愿推荐中的“冷启动”问题?
标准答案:冷启动分两种情况——
新用户冷启动:通过渐进式问卷采集偏好(每次聚焦1个决策维度),结合贝叶斯算法实时调整后续问题逻辑,快速构建用户画像。
新物品冷启动:利用院校属性特征进行内容过滤,同时结合图嵌入技术,通过相似专业推断新院校的推荐优先级。
踩分点:区分用户冷启动和物品冷启动 + 给出具体解决方案。
Q4:RAG技术在AI志愿填报系统中扮演什么角色?
标准答案:RAG(Retrieval-Augmented Generation,检索增强生成)通过将大模型与外部知识库(历年录取数据、招生政策、院校信息)结合,先检索相关权威信息,再让模型基于检索结果生成回答。这一技术能有效缓解大模型的“幻觉”问题,确保推荐结果有据可依,提升推荐权威性与可信度。
踩分点:解释RAG全称 + 说明“检索+生成”机制 + 点出缓解幻觉的作用。
八、结尾总结
本文从传统志愿填报的痛点切入,系统梳理了AI志愿推荐的核心技术体系。核心要点回顾:
两大基础算法:协同过滤(基于群体行为相似性)与内容过滤(基于物品属性相似性),二者互补协同,现代系统普遍采用混合推荐策略。
三大前沿技术:图嵌入挖掘院校专业深层关联、RAG提升推荐权威性、多智能体协同优化系统稳定性。
“冲稳保”三层推荐:基于录取概率预测的分层策略,是AI志愿填报的核心输出形式。
重点强调:AI志愿推荐并非单一算法可以解决,而是多算法融合 + 大模型增强的复杂系统工程。下一篇文章将深入讲解RAG技术的工程落地——如何构建向量数据库、设计检索策略、优化生成质量,敬请期待!